Après quelques années d’absence, j’ai eu le plaisir de participer à nouveau au France Cybersecurity Challenge qui vient de se terminer. C’est une compétition de cybersécurité organisée par l’ANSSI consistant à résoudre des épreuves en temps limité. Les épreuves étaient cette année comme d’habitude très originales et de difficultés variées, ce qui en fait une de mes compétitions préférées et que je m’amuse beaucoup même si je ne fais de la cybersécurité qu’en amateur et une semaine par an.
Cette année, je me suis concentré sur les épreuves de hardware, forensics et « tutti frutti » de la catégorie misc. Ce qui est un peu frustrant pendant le concours, mais ce que j’aime bien finalement, c’est que les techniques qui me sont utiles une année semblent ne jamais beaucoup m’aider les années suivantes, ce qui fait que je dois constamment réinventer des méthodes et apprendre de nouvelles choses. C’est pas plus mal et c’est une des raisons pour lesquelles j’aime beaucoup cette compétition. Bref, passons au vif du sujet avec les writeups de quelques épreuves que j’ai le plus appréciées.
Crypto
This is fine
On avait une liste de polynômes entiers (de degré 16 et avec des nombres très grands), un par lettre du flag. Pour chaque polynôme \(P\), il fallait trouver un \(x\) entier tel que \(P(x) = c\) avec \(0 \leq c < 256\). Ça semble compliqué à première vue (il y a beaucoup de \(x\) à tester), mais il y a une astuce. Décomposons :
\[\begin{align*} P(x) &= c\\ a_n x^n + \cdots + a_2 x^2 + a_1 x + a_0 &= c\\ (a_n x^{n-1} + \cdots + a_2 x + a_1) x &= c - a_0\\ \end{align*}\]
Par conséquent, \(x\) est un diviseur de \(c - a_0\) (ou son opposé). Comme il n’y a que 256 valeurs de \(c\) possibles, on peut donc les énumérer, et pour chacune énumérer les diviseurs de \(c - a_0\), et regarder si un de ces nombres satisfait \(P(x) = c\) (ou \(P(-x) = c\)). Ça se fait très bien avec sympy.
Hardware
Convolu-quoi ?
Le flag était d’abord décomposé en une séquence binaire, puis on regardait une fenêtre glissante de 8 bits sur cette séquence et on enregistrait deux valeurs à chaque offset : la parité de state & G0 et celle de state & G1 avec G0 et G1 deux uint8s. On nous donnait le résultat de cette convolution.
On pouvait donc simplement deviner les bits du flags les uns après les autres, en essayant d’ajouter un 0 ou un 1 et en regardant si ça correspondait avec le flag encodé. Il y avait sûrement plus malin et efficace mais ça suffisait largement.
Maintenant, l’ESP !
En ouvrant le fichier avec wireshark, il m’a sauté aux yeux que le dernier octet des premiers blocs data.data formaient FCSC. J’ai commencé par sélectionner tous ces blocs avec
tshark -r capture.pcapng -e data.data -Tfields | cut -c25-26 | tr -d '\n' | xxd -r -pJ’ai obtenu un flag avec semble-t-il toutes les lettres en doubles, mais en les dédoublant j’ai obtenu un flag invalide. En regardant de plus près les échanges, ils étaient bidirectionnels : probablement un message et sa confirmation. Or, certains paquets manquaient : parfois le message, et parfois sa confirmation (mais jamais les deux heureusement). J’ai donc dédoublé les lettres à la main, ce qui m’a probablement pris plus de temps que d’écrire un script pour ce faire mais avait l’avantage de ne pas demander de réfléchir.
Tortoise Say
J’adore ce genre d’épreuves. On avait un enregistrement réalisé par un analyseur logique de la programmation d’un écran e-ink et il fallait retrouver ce qui était affiché à l’écran.
J’ouvre le fichier vcd avec Pulseview, j’ajoute un décodeur SPI (comme suggérait la doc de l’écran) en associant les bonnes bornes aux bon fils, et ça me décode les octets.
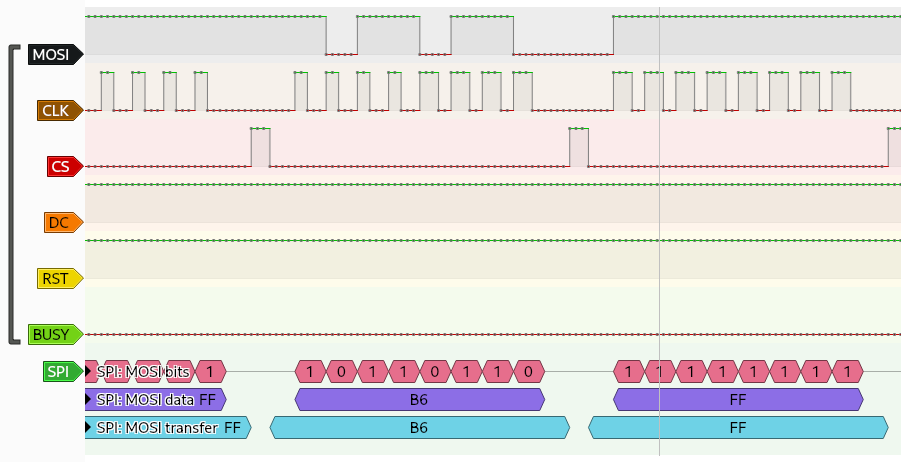
J’enregistre les octets dans un fichier que j’analyse avec Python.
Visuellement, Pulseview montrait aussi des pulses d’activité à intervalles réguliers, j’ai interprété ça comme des frames. En comptant le nombre d’octets par frames, ça faisait à peu près le nombre de pixels de l’écran (ou peut-être deux fois ce nombre je crois), ce qui a confirmé mon intuition. J’ai donc créé un tableau de la taille de l’écran et l’ai rempli avec les valeurs des octets, puis affiché avec matplotlib. Il a fallu que je m’y reprenne à plusieurs fois pour gérer le petit-endian (ou grand endian) et le sens de remplissage.
Transport me too
Pareil, une épreuve que j’ai beaucoup aimée. On avait accès à une carte de transport de STMicroElectronics, et il fallait lui envoyer des commandes pour lui permettre de faire 1000 voyages alors qu’elle n’en autorisait normalement qu’un maximum de 5.
Il suffisait de télécharger la documentation de la carte sur le site de STM, qui expliquait le format des commandes à envoyer pour lire et écrire dans les registres de la carte. Ils donnaient même un fichier C implémentant le code de vérification utilisé à chaque message, que j’ai traduit en Python.
Ce qui m’a fait lire la doc plusieurs fois, c’est que certains registres n’étaient débloqués en écriture qu’une fois après avoir modifié d’autres registres, et que ces registres-là n’étaient modifiables que vers le bas (une fois un 0 écrit c’était définitif). Il fallait donc faire un petit jeu de modifier tel registre pour débloquer tel autre pour pouvoir voyager 32 fois de plus, et de faire ça autant de fois que nécessaire pour arriver à 1000.
Forensics
J’ai résolu 5 épreuves sur 7 dans cette catégorie mais je suis loin d’être le seul. Elles fournissaient des logs d’accès, d’activité ou de connexion entre machines, et il fallait trouver des activités suspectes. J’ai résolu ça grâce à une utilisation intensive de grep.
Misc
Times Square
C’était une connexion ssh qui ne donnait un message que si la taille du terminal était suffisamment grande. Même avec la fonte la plus petite, impossible de créer une taille suffisamment grande en redimensionnant la fenêtre. Heureusement il existe une commande stty cols 50000 rows 40000 qui aide à définir une taille arbitraire. Mais du coup le message était affiché au milieu de la fenêtre, hors de l’écran. Là je pense qu’il y avait peut-être une meilleure méthode, mais j’ai pipé la connexion ssh dans un fichier pour le lire (un peu laborieusement). Impossible de me souvenir comment j’avais fait pendant la compétation, mais là en m’y repenchant au calme j’ai écrit un script pour parser les codes d’affichage en les changeant pour les faire rentrer dans une fenêtre de taille raisonnable.
Ça donnait donc la condition un peu énigmatique suivante : X + Y + t = 42 && X > 300 && Y > 200 (t était un compteur de secondes qui commençait à 0 quand on se connectait). Mais comme ces valeurs sont sur 16 bits, il suffisait de sommer à 2^16 + 42 : stty cols 50000 rows 15578 et le flag était affiché à la première seconde.
Tunnel routier (1/2)
J’ai bien galéré sur cette épreuve, je crois que c’est parce que j’y ai travaillé pendant une coupure du service, ce qui faisait que la connexion ne me retournait absolument rien et je croyais que c’était ma faute.
Les infos utiles étaient volontairement dissimulées dans l’énoncé, avec des formulations vagues comme « un protocole industriel sur le port TCP/502 ». Wikipedia m’apprend que le port 502 est en général utilisé pour le protocole Modbus, qui semble complètement approprié pour gérer un automate tel que décrit dans l’épreuve. Je télécharge donc pymodbus qui me permet de me connecter.
L’énoncé disait qu’un token était caché dans les données d’identification de l’automate, un coup d’œil à l’API de pymodbus m’indique une fonction read_device_information qui me semble prometteuse, bingo.
J’ai pas réussi à faire la partie 2 qui semblait être plus intéressante.
FizzBuzz (1/2 et 2/2)
J’ai vraiment aimé ces deux épreuves, qui consistaient simplement à programmer le programme classique FizzBuzz en assembleur. Dans la deuxième épreuve, on n’avait pas le droit au modulo ni à la division (des instructions assez naturelles pour programmer FizzBuzz), donc j’ai implémenté un modulo à la main avec des soustractions, avant de me rendre compte qu’il fallait être un peu efficace parce qu’on était limité à 65536 cycles de processeur (c’est un peu short pour un FizzBuzz jusqu’à 1000, sans modulo, si on ne fait pas un peu attention). J’ai vraiment adoré écrire ces programmes et les optimiser.
Las Vegas Baby
Ahh, peut-être mon épreuve préférée, en tout cas la plus dure que j’ai résolue (on est seulement 25 à l’avoir réussie) et rien à voir avec de la cybersécurité (mais ça change un peu et c’est rafraîchissant). On avait l’énoncé suivant :
Vous êtes à Las Vegas, en plein tournoi de poker Texas Hold’em. Tous les joueurs sont partis en pause, et vous vous retrouvez seul avec le paquet de cartes et votre conscience. L’envie vous prend alors de tricher.
Cependant, la tâche n’est pas si facile: le croupier coupe le deck à une position aléatoire avant la distribution des cartes. Il vous faut alors être malin pour que la distribution vous donne le meilleur jeu, quel que soit la coupe effectuée par le croupier. De plus, vous savez que vous allez être à la petite blinde, mais ne savez pas encore si il y aura 3 ou 4 joueurs après la pause.
Votre objectif est de trier le paquet de carte de manière à être certain de gagner la prochaine main.
C’est original et amusant ! J’ai vu ça comme un problème d’optimisation / de programmation par contraintes. Pour la programmation par contraintes ou la satisfiabilité, ça m’aurait demandé d’implémenter les mains de poker en un langage de contraintes et ça avait l’air pénible, je n’avais pas envie de m’infliger ça. Idem pour l’optimisation ILP. J’ai donc décidé de prendre la fonction d’évaluation des mains comme une boîte noire, et d’utiliser une méta-heuristique, celle avec laquelle je suis le plus familier, soit le recuit simulé. C’est une méthode particulièrement adaptée aux problèmes où l’on peut transformer graduellement un état en un autre (un état étant ici un deck, qu’on peut réordonner petit à petit).
À chaque étape, on propose un changement aléatoire et assez élémentaire à l’état (par exemple, échanger deux cartes prises au hasard dans le deck). Ce changement peut faire augmenter ou diminuer le score (le nombre de mains remportées). Si ça améliore le score on garde le changement, et si ça rend le score moins bon on le garde avec une certaine probabilité qui dépend de la différence de score, et d’un paramètre qu’on nomme habituellement la température. Plus la température est élevée, plus la probabilité de conserver des changements qui détériorent le score est élevée, et avec une température de zéro, on ne garde que les changements qui améliorent le score. On commence avec une température très élevée (pour pouvoir bien explorer l’espace d’états possibles), et on diminue progressivement la température pour se concentrer sur les meilleurs scores.
Cet algorithme a été très étudié pendant des décennies, et il s’adapte à beaucoup de problèmes, mais ce n’est pas forcément évident de choisir une bonne fonction de score, une bonne fonction de proposition (les étapes élémentaires qu’on utilise pour passer d’un état à un autre état voisin), et un bon programme de refroidissement. Si on refroidit trop vite on peut se retrouver bloqué dans un optimum local, et si on refroidit trop lentement ben ça prend trop de temps1.
Bon, comme ça demande en général beaucoup d’étapes, il faut que l’évaluation soit rapide et j’ai donc RIIR le programme d’exemple qu’on nous fournissait en Python. Ça m’a permis de multiplier par 15000 la vitesse d’évaluation, et passer de ~2 decks évalués par seconde à ~30000. Vive Rust.
Au lieu de manipuler un paramètre de température je trouve en général plus pratique d’utiliser son inverse. J’ai donc commencé par une température inverse de 0 (donc température infinie : tous les mouvements sont acceptés) que je faisais augmenter linéairement. En traçant le nombre de mains perdues (que je cherchais donc à minimiser) en fonction de la température, j’ai vu une descente assez régulière jusqu’à une température inverse de 2,5, puis une descente beaucoup plus lente, qui est quand même descendue à 2 mais est restée bloquée là.

Ça m’a montré que ce n’est pas forcément la peine de s’attarder sur la première phase, mais que la température inverse critique semble être 2,5 et que c’est probablement à ce moment-là et après qu’il faut particulièrement insister.
J’ai donc un peu changé le programme de refroidissement : j’ai commencé à 2, et quand j’arrivais à 10 je considérais que j’étais bloqué dans un minimum local dont il fallait sortir. Pour ça, je redescendais tout à coup la température inverse à 2 et je recommençais (les fameux recuits).
J’ai lancé un run et je suis allé me coucher, quand je me suis réveillé ça avait trouvé une solution, au bout de 2h30 de calcul et 236 millions de decks testés. Vive le recuit simulé.
Notes de bas de page
Mais ce que je trouve incroyable c’est qu’on peut démontrer que si on refroidit suffisamment lentement, on arrive forcément à l’optimum global ! Le hic c’est que ça peut prendre des siècles.↩︎