Interpretable machine learning models and debugging, explanation, and fairness techniques offer tremendous intellectual, social, and commercial potential (please refer to the two previous posts: 1. Context and 2. State of the art). This post addresses their limitations and precautions to take.
Just as other technologies, machine learning explanations can be abused. Here are the most important abuses:
- Fairwashing: use explanations as a faulty safeguard for harmful black boxes to make a biased model appear fair.
- Hacking. Explanations can be used to steal predictive models or sensitive training data, as well as to plan other more sophisticated attacks.
Even beyond these malicious intents, we still need to care about some particularities of the interpretability mechanics: (1) explanation ≠ trust, (2) good models are many, (3) explanatory potential of the surrogate models.
1. Explanations alone are not sufficient for trust
Explanations alone improve understanding and appeal, but not trust. Explanation as a concept is related directly to understanding and transparency but not directly to trust. Basically, one can understand and explain a model without trusting it. Or you can also trust a model and not be able to understand or explain it.
Explanation and understanding without trust.
The following image show us a machine learning model which isn’t trustworthy: it is too dependent on one input variable, PAY_0. The model makes many errors because of its overemphasis of that variable (source).
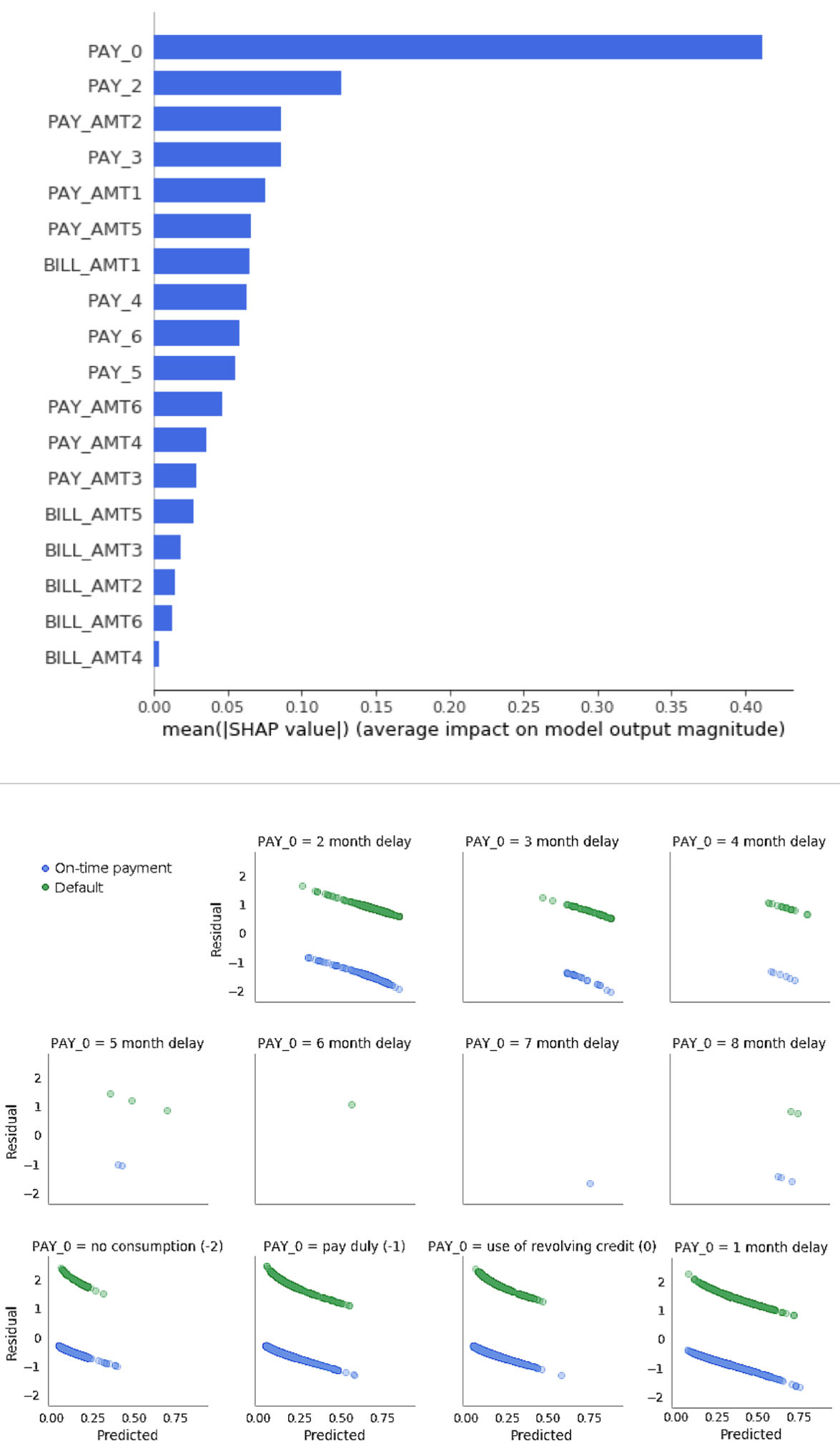
The global Shapley explanations and residual analysis identify a pathology in an unconstrained GBM model trained to predict credit card default. The GBM overemphasizes the input variable PAY_0 (customer’s most recent repayment status). Because of this overemphasis of PAY_0, the GBM usually can’t predict on-time payment if recent payments are delayed (PAY_0 > 1), causing large negative residuals. The GBM also usually can’t predict default if recent payments are made on time (PAY_0 ≤ 1), causing large positive residuals. In this scenario, a machine learning model is explainable, but not trustworthy.
Trust without explanation and understanding.
Historically, several black-box predictive models were used for fraud detection (1, 2) in FinTech: autoencoders, MLP neurla networks. Though they weren’t well understood or explainable by contemporary standards, they were trusted when they performed well.
If the goal is to have trustworthy models is your goal, then explanations alone are not sufficient. However, in an ideal setting, explanation techniques combined a wide variety of other methods could help to increase accuracy, fairness, interpretability, privacy, security, and trust in ML models.
2. Good Models are Many
If we fix the set of input variables and prediction targets, complex machine learning strategies can produce multiple accurate models of different architectures. The details of explanations and fairness depend heavily on the architecture and can change drastically across multiple accurate, similar models trained on the same data.
This problem is referred to as «the multiplicity of good models» (L.Breiman) or «model locality» (credit scoring) and means that in almost every debugging, explanation, or fairness exercise, the complex machine learning model we choose to debug, explain, audit for fairness is just one of many, many similar models.
Let’s discuss why this happens and what can be done to address it.
The following figures illustrate the surfaces of error functions for two fictitious predictive models. The left one is representative of a traditional linear model’s error function: the surface is convex with a clear global minimum which the most accurate model would approach. The location of this minimum of the error function, the weights for the inputs would not change very much if the model was retrained, even if the input data about a customer’s income and interest rate changed a little bit.
| Arror surface of a traditional linear model | An illustration of the error surface of a ML model |
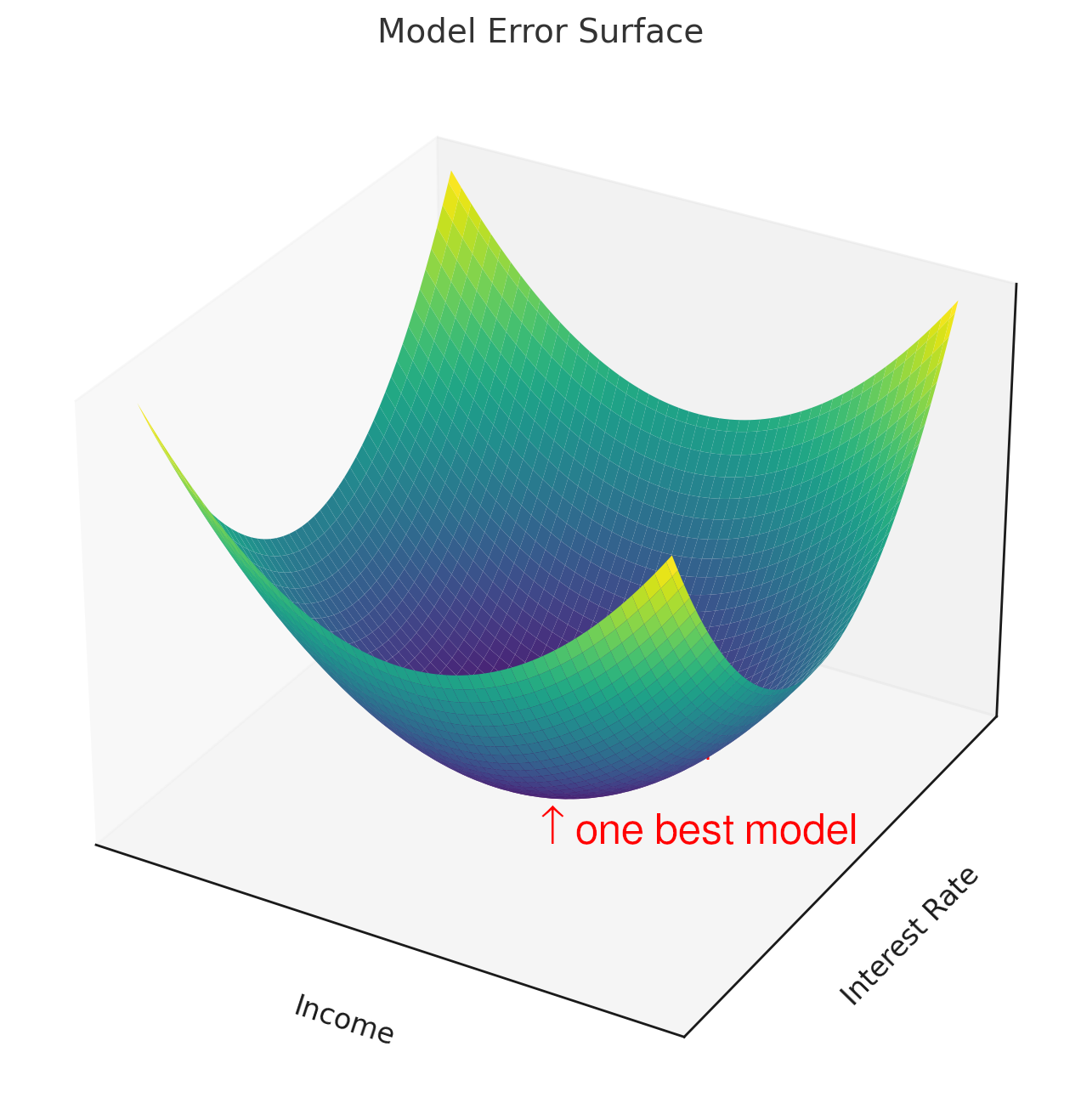 |
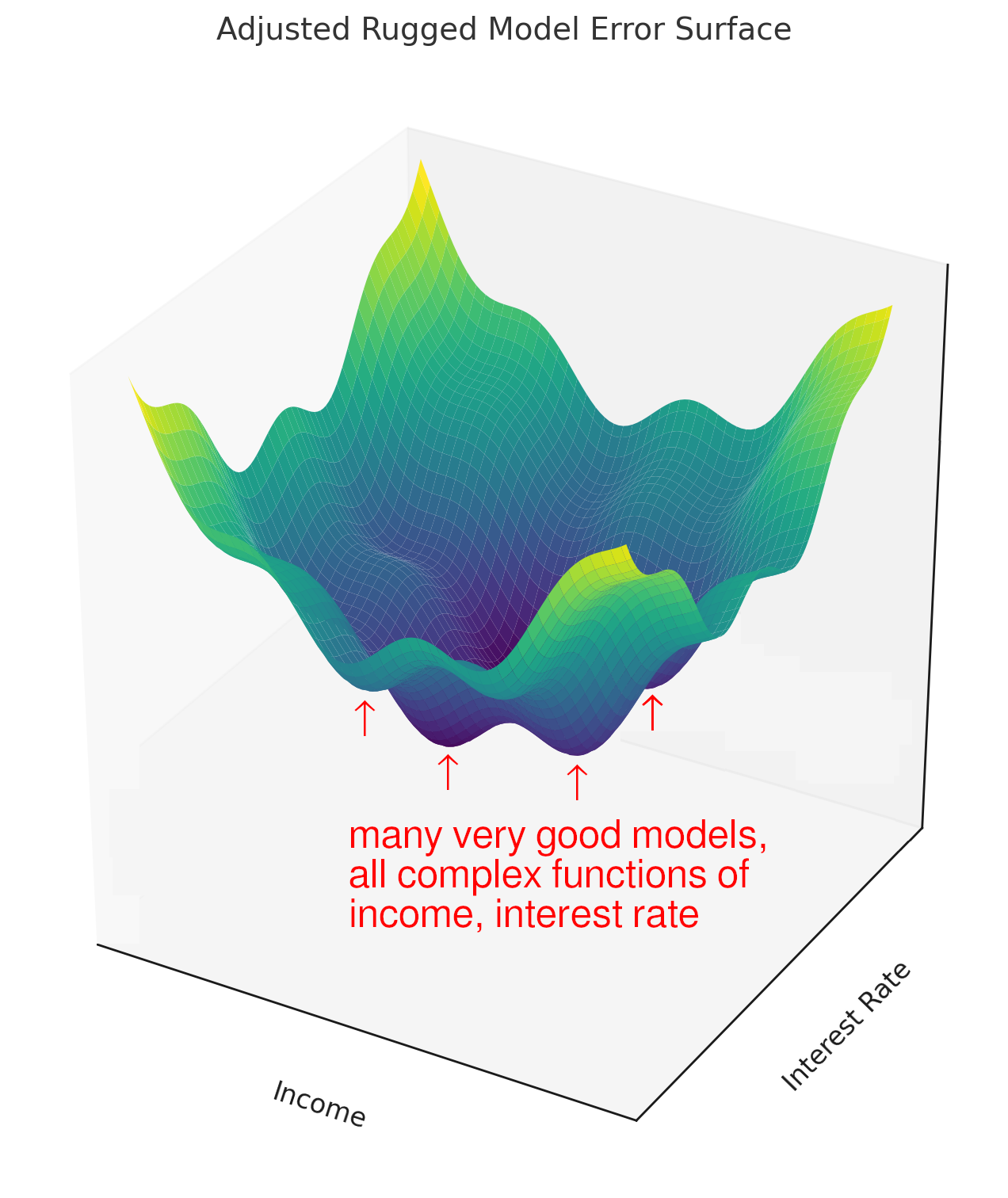 |
Since the error surface for linear models is convex, there is only one best model (given the stability of traning data). The model associated with the left error surface is said to have «strong model locality». Even if we retrained the model on new or updated data, the weight of income versus interest rate is likely mostly stable in the pictured error function and its associated linear model. Explanations about how the function made decisions about loan defaults based on those two inputs would also probably be stable and so would results for disparate impact testing.
The picture on the right depicts a nonconvex error surface representative of the error function for a ML model. It is nonconvex and has no obvious global minimum: there are many different ways a complex machine learning algorithm could learn to weigh a customer’s income and a customer’s interest rate to make an accurate decision about when they might default. Each of these different weightings would create a different function for making loan default decisions, and each of these different functions would have different explanations and fairness characteristics. This would be obvious upon updating training data and trying to refit a similar machine learning model.
There is no remedy to the multiplicity of good models challenge in machine learning. Partial solutions might include:
- perturbations of numerous similar models are often well traced by Shapley values.
- constrained interpretable models are good at maintaining an accurate, stable, and representative predictions that won’t change too much if the training data were updated.
The multiplicity of good models might play it to our advantage in some situations: of the many ML models trainable on a given dataset, it might be possible to find one with the desired accuracy, explanation, and fairness characteristics.
Limitations of Surrogate Models
Surrogate models are important explanation and debugging tools.
They can provide global and local insights into both model predic‐
tions and model residuals or errors. However, surrogate models are
approximate. There are few theoretical guarantees that the surrogate
model truly represents the more complex original model from
which it has been extracted. Let’s go over the rationale for surrogate
models and then outline the nuances of working with surrogate
models responsibly. Linear models, and other types of more
straightforward models, like the function in Figure 1-9, create
approximate models with neat, exact explanations. Surrogate models
are meant to accomplish the converse (i.e., approximate explana‐
tions for more exact models). In the cartoon illustrations in Figures
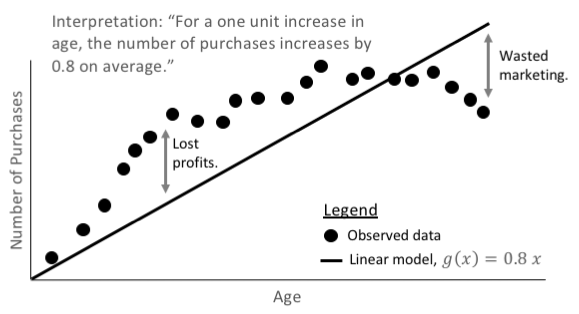 1-9 and 1-10, we can see the benefit of accurate and responsible use
of surrogate models. The explanation for the simple interpretable
model in Figure 1-9 is very direct, but still doesn’t really explain the
modeled age versus purchasing behavior because the linear model
just isn’t fitting the data properly.
1-9 and 1-10, we can see the benefit of accurate and responsible use
of surrogate models. The explanation for the simple interpretable
model in Figure 1-9 is very direct, but still doesn’t really explain the
modeled age versus purchasing behavior because the linear model
just isn’t fitting the data properly.
Figure 9. A linear model, g(x), predicts the average number of purcha‐ ses given a customer’s age. The predictions can be inaccurate but the associated explanations are straightforward and stable. (Figure cour‐ tesy of H2O.ai.)
Although the explanations for the more complex machine learning function in Figure 1-10 are approximate, they are at least as useful, if not more so, than the linear model explanations above because the underlying machine learning response function has learned more exact information about the relationship between age and purcha‐ ses. Of course, surrogate models don’t always work out like our car‐ toon illustrations. So, it’s best to always measure the accuracy of your surrogate models and to always pair them with more direct explanation or debugging techniques.
When measuring the accuracy of surrogate models, always look at the R2, or average squared error (ASE), between your surrogate model predictions and the complex response function you are try‐ ing to explain. Also use cross-validated error metrics for decision tree surrogate models. Single decision trees are known to be unsta‐ ble. Make sure your surrogate decision trees have low and stable error across multiple folds of the dataset in which you would like to create explanations.
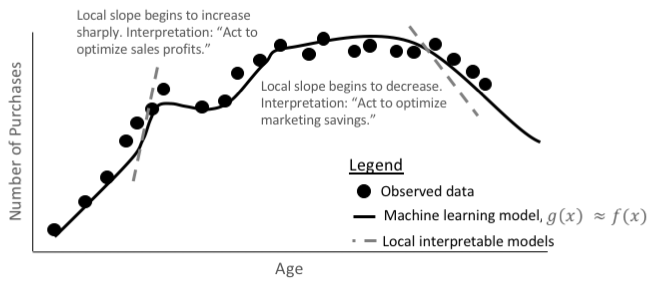 Figure 10. A machine learning model, g(x), predicts the number of
purchases, given a customer’s age, very accurately, nearly replicating
the true, unknown signal-generating function, f(x). (Figure courtesy of
H2O.ai.)
Figure 10. A machine learning model, g(x), predicts the number of
purchases, given a customer’s age, very accurately, nearly replicating
the true, unknown signal-generating function, f(x). (Figure courtesy of
H2O.ai.)
Additionally, there are many options to pair surrogate models with more direct techniques. In Figures 1-2 and 1-3 we’ve already shown how to pair decision tree surrogate models with direct plots of model predictions (i.e., ICE and partial dependence curves) to find and confirm interactions. You can pair Shapley values with LIME coefficients to see accurate point estimates of local variable impor‐ tance and the local linear trends of the same variables. You can also pair decision tree surrogate models of residuals with direct adversa‐ rial perturbations to uncover specific error pathologies in your machine learning models, and you can probably think of several other ways to combine surrogate models and direct explanation, fairness, or debugging techniques. Just remember that if your surro‐ gate model is not an accurate representation of the model you are trying to explain, or if surrogate model explanations don’t match up with more direct explanation techniques, you probably should not use surrogate models for the interpretability task at hand.
Testing Interpretability and Fairness
The novelty and limitations of interpretable machine learning might call into question the trustworthiness of debugging, explanation, or fairness techniques themselves. Don’t fret! You can test these techni‐ ques for accuracy too. Originally, researchers proposed testing machine learning model explanations by their capacity to enable humans to correctly determine the outcome of a model prediction based on input values.45 Given that human evaluation studies are likely impractical for some commercial data science or machine learning groups, and that we’re not yet aware of any formal testing methods for debugging or fairness techniques today, several poten‐ tial approaches for testing debugging, explanations, and fairness techniques themselves are proposed here:
- Simulated data You can use simulated data with known characteristics to test debugging, explanation, and fairness techniques. For instance, models trained on totally random data with no relationship between a number of input variables and a prediction target should not give strong weight to any input variable, nor gener‐ ate compelling local explanations or reason codes. Nor should they exhibit obvious fairness problems. Once this baseline has been established, you can use simulated data with a known sig‐ nal generating function to test that explanations accurately rep‐ resent that known function. You can simulate data with known global correlations and local dependencies between demo‐ graphic variables, or other proxy variables, and a prediction tar‐ get and ensure your fairness techniques find these known group and individual fairness issues. You can also switch labels for classification decisions or inject noise into predicted values for regression models and check that model debugging techniques find the simulated errors. Of course, this kind of empirical test‐ ing doesn’t guarantee theoretical soundness, but it can certainly help build the case for using debugging, explanation, and fair‐ ness techniques for your next machine learning endeavor.
- Explanation and fairness metric stability with increased prediction accuracy Another workable strategy for building trust in explanation and fairness techniques may be to build from an established, previ‐ ously existing model with known explanations and acceptable fairness characteristics. Essentially, you can perform tests to see how accurate a model can become or how much its form can change before its predictions’ reason codes veer away from known standards and its fairness metrics drift in undesirable 45 Doshi-Velez and Kim, “Towards a Rigorous Science of Interpretable Machine Learn‐ ing.” ways. If previously known, accurate explanations or reason codes from a simpler linear model are available, you can use them as a reference for the accuracy of explanations from a related, but more complex and hopefully more accurate, model. The same principle likely applies for fairness metrics. Add new variables one by one or increase the complexity of the model form in steps, and at each step make sure fairness metrics remain close to the original, trusted model’s measurements.
- Debugging explanation and fairness techniques with sensitivity analy‐ sis and adversarial examples If you agree that explanations and fairness metrics likely should not change unpredictably for minor or logical changes in input data, then you can use sensitivity analysis and adversarial exam‐ ples to debug explanation and fairness techniques. You can set and test tolerable thresholds for allowable explanation or fair‐ ness value changes and then begin manually or automatically perturbing input data and monitoring for unacceptable swings in explanation or fairness values. If you don’t observe any unnerving changes in these values, your explanation and fair‐ ness techniques are likely somewhat stable. If you do observe instability, try a different technique or dig in and follow the trail the debugging techniques started you down.
Machine Learning Interpretability in Action
To see how some of the interpretability techniques discussed in this report might look and feel in action, a public, open source reposi‐ tory has been provided. This repository contains examples of white-box models, model visu‐ alizations, reason code generation, disparate impact testing, and sen‐ sitivity analysis applied to the well-known Taiwanese credit card customer dataset using the popular XGBoost and H2O libraries in Python.46 46 D. Dua and C. Graff, UCI Machine Learning Repository, University of California Irvine, School of Information and Computer Science, 2019. https://oreil.ly/33vI2LK.
What’s next?
FATML, XAI, and machine learning interpretability are new, rapidly changing, and expanding fields. Automated machine learning (autoML) is another important new trend in artificial intelligence. Several open source and proprietary software packages now build machine learning models automatically with minimal human inter‐ vention. These new autoML systems tend to be even more complex, and therefore potentially black box in nature, than today’s somewhat human-oriented data science workflows. For the benefits of machine learning and autoML to take hold across a broad cross-section of industries, our cutting-edge autoML systems will also need to be understandable and trustworthy.
In general, the widespread acceptance of machine learning inter‐ pretability techniques will be one of the most important factors in the increasing adoption of machine learning and artificial intelli‐ gence in commercial applications and in our day-to-day lives. Hope‐ fully, this report has convinced you that interpretable machine learning is technologically feasible. Now, let’s put these approaches into practice, leave the ethical and technical concerns of black-box machine learning in the past, and move on to a future of FATML and XAI.