Source : Borg, I., Groenen, P., Modern Multidimensional Scaling : Theory and Applications, Second Edition, Springer, 2005.
On désigne sous le terme de MDS (multidimensional scaling), un ensemble de techniques permettant de représenter les données d'une matrice de proximités entre objets à l'aide de modèles de distances spatiales. Dans sa version la plus simple, la méthode MDS permet de retrouver une carte bi-dimensionnelle à partir d'un ensemble de distances mutuelles entre lieux.
Le MDS classique est une méthode est fondée sur les travaux de Torgerson (1952, 1958) et Gower. Elle est appelée Classical MDS, AFTD (analyse factorielle sur un tableau de distances), Principal Coordinates Analysis, ou encore Analyse du triple (Benzécri).
Principe mathématique : on calcule les valeurs propres et vecteurs propres d'une matrice calculée à partie de la matrice de proximités, afin de déterminer la "meilleure" projection de l'ensemble d'objets dans un sous-espace de dimension donnée.
Algorithme :
On dispose au départ de la matrice n x n des "distances" mutuelles entre n objets. On souhaite obtenir une représentation de ces n objets dans un espace de dimension m en respectant "au mieux" les distances entre les objets. La dimension m de l'espace n'est pas fixée a priori.
Remarque :
Si la matrice P de départ est une matrice de distances euclidiennes, le MDS classique fournit en résultat les coordonnées des n points, à une rotation près, dans un repère dont l'origine est le centre de gravité des points.
Propriété de minimalité de la solution :
On montre que la solution trouvée minimise la fonction de perte (appelée Strain, littéralement Contrainte, par Carrol et Chang) :
L(X) = || XX' - B ||
où X représente la matrice d'un système de n points (les variables) dans un espace de dimension n et ou la norme utilisée pour la matrice est la norme de Fröbenius, c'est-à-dire la racine carrée de la somme des carrés de tous les coefficients de la matrice. C'est en ce sens que la solution trouvée respecte "au mieux" les proximités entre objets. En particulier, si la matrice de départ est une matrice de distances euclidiennes, on obtient : Strain = 0.
Variante :
On fixe a priori le nombre m de valeurs propres à garder. On conserve alors les m plus grandes valeurs propres où les valeurs propres strictement positives, si ces dernières sont en nombre inférieur à m. Une propriété intéressante du MDS classique est que les dimensions sont emboîtées. Ainsi les deux premières dimensions d'une solution avec m=3 sont les mêmes que celles d'une solution avec m=2. Cette propriété ne se retrouve pas pour le MDS métrique (visant à minimiser le Stress).
La solution trouvée déforme alors "au minimum" les distances entre objets, tout en respectant la contrainte sur la dimension de l'espace des solutions.
Remarque.
Si P est une matrice de distances, le MDS métrique tel qu'il est décrit ici est équivalent à l'ACP avec une métrique M=I, comme on peut s'en rendre compte sur l'exemple "notes d'élèves" (cf exemple 2).
Enoncé :
Source : Handbook of Statistics - Elsevier 2007
On se donne les distances à vol d'oiseau entre 10 villes américaines.
Les données se présentent sous la forme suivante :
| Atl | Chi | Den | Hou | LA | Mia | NY | SF | Sea | DC | |
| Atl | 0 | 587 | 1212 | 701 | 1936 | 604 | 748 | 2139 | 2182 | 543 |
| Chi | 587 | 0 | 920 | 940 | 1745 | 1188 | 713 | 1858 | 1737 | 597 |
| Den | 1212 | 920 | 0 | 879 | 831 | 1726 | 1631 | 949 | 1021 | 1494 |
| Hou | 701 | 940 | 879 | 0 | 1374 | 968 | 1420 | 1645 | 1891 | 1220 |
| LA | 1936 | 1745 | 831 | 1374 | 0 | 2339 | 2451 | 347 | 959 | 2300 |
| Mia | 604 | 1188 | 1726 | 968 | 2339 | 0 | 1092 | 2594 | 2734 | 923 |
| NY | 748 | 713 | 1631 | 1420 | 2451 | 1092 | 0 | 2571 | 2408 | 205 |
| SF | 2139 | 1858 | 949 | 1645 | 347 | 2594 | 2571 | 0 | 678 | 2442 |
| Sea | 2182 | 1737 | 1021 | 1891 | 959 | 2734 | 2408 | 678 | 0 | 2329 |
| DC | 543 | 597 | 1494 | 1220 | 2300 | 923 | 205 | 2442 | 2329 | 0 |
Ces données sont enregistrées au format .csv d'Excel dans le fichier : FlyingMileage.csv avec la structure indiquée ci-dessus.
On peut les charger dans R à l'aide de la commande :
> distances <- read.csv2("FlyingMileage.csv")
N.B. read.csv2 permet de lire des données au format "table", avec les spécifications par défaut suivantes : séparateur = ";", séparateur décimal = ",".
On utilise la commande cmdscale, qui se trouve dans le package MASS.
> library(MASS)
> cmdscale(distances[,2:11])
[,1] [,2]
Atl -718.7594 142.99427
Chi -382.0558 -340.83962
Den 481.6023 -25.28504
Hou -161.4663 572.76991
LA 1203.7380 390.10029
Mia -1133.5271 581.90731
NY -1072.2357 -519.02423
SF 1420.6033 112.58920
Sea 1341.7225 -579.73928
DC -979.6220 -335.47281
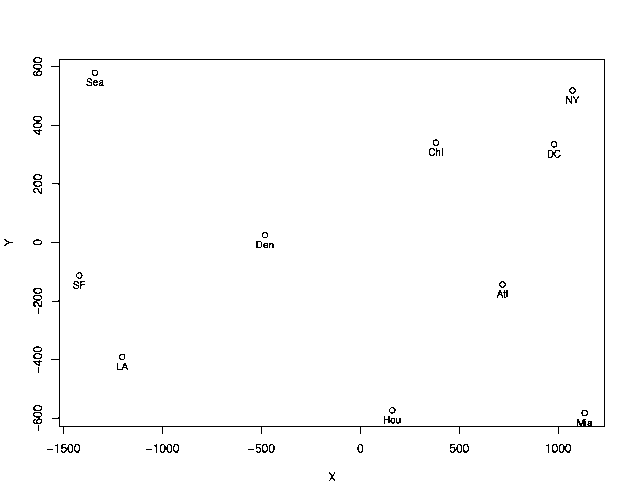
On voit que l'orientation des axes est à l'opposé des conventions utilisées pour les cartes de géographie.
On prend donc les opposés des coordonnées sur les deux axes :
> Y <- - cmdscale(distances[,2:11])[,2]
> X <- - cmdscale(distances[,2:11])[,1]
On trace ensuite le graphique et les étiquettes des points :
> plot(X,Y,type="p")
> text(X,Y,distances[,1],pos=1,cex=0.8)
Résultat obtenu :
On peut choisir la dimension de l'espace dans lequel le résultat est recherché.
Pour une solution en dimension 3 :
> cmdscale(distances[,2:11],k=3)
On se donne les notes de 9 sujets dans 5 matières. Les données, après centrage et réduction, sont les suivantes (cf fichier Mini-ACP.csv):
|
Sujet
|
Math
|
Sciences
|
Francais
|
Latin
|
Musique
|
|
Jean
|
-1,0865
|
-1,2817
|
-1,5037
|
-1,6252
|
-1,019
|
|
Aline
|
-0,4939
|
-0,613
|
-0,6399
|
-0,7223
|
-0,6794
|
|
Annie
|
-1,0865
|
-0,9474
|
0,2239
|
-0,1806
|
0
|
|
Monique
|
1,4322
|
1,5604
|
1,5197
|
1,8058
|
-1,019
|
|
Didier
|
1,284
|
1,3932
|
0,5119
|
0,7223
|
-0,3397
|
|
André
|
0,3951
|
0,0557
|
-1,3597
|
-1,0835
|
0,6794
|
|
Pierre
|
-1,2347
|
-0,9474
|
1,0878
|
0,5417
|
-0,3397
|
|
Brigitte
|
0,9877
|
0,8916
|
-0,4959
|
-0,1806
|
0,3397
|
|
Evelyne
|
-0,1975
|
-0,1115
|
0,6559
|
0,7223
|
2,3778
|
On importe les données dans R :
> Mini <- read.csv2("Mini-ACP.csv")
> Mini
Sujet Math Sciences Francais Latin Musique
1 Jean -1.087 -1.2817 -1.504 -1.625 -1.02
2 Aline -0.494 -0.6130 -0.640 -0.722 -0.68
3 Annie -1.087 -0.9474 0.224 -0.181 0.00
4 Monique 1.432 1.5604 1.520 1.806 -1.02
5 Didier 1.284 1.3932 0.512 0.722 -0.34
6 Andr<8e> 0.395 0.0557 -1.360 -1.083 0.68
7 Pierre -1.235 -0.9474 1.088 0.542 -0.34
8 Brigitte 0.988 0.8916 -0.496 -0.181 0.34
9 Evelyne -0.198 -0.1115 0.656 0.722 2.38
On isole les données numériques dans une matrice :
> MXM <- MMM[,2:6]
On calcule la matrice des distances euclidiennes entre les sujets :
> dxd <- dist(MXM)
> dxd
1 2 3 4 5 6 7 8
2 1.57
3 2.49 1.40
4 5.94 4.43 4.39
5 4.78 3.27 3.48 1.64
6 2.68 1.93 2.64 4.78 3.22
7 3.47 2.31 1.19 3.96 3.49 3.65
8 3.74 2.41 2.88 3.24 1.62 1.65 3.44
9 4.89 3.67 2.85 4.35 3.44 3.25 3.06 2.95
On réalise le positionnement multidimensionnel :
> cmdscale(dxd,k=3)
[,1] [,2] [,3]
[1,] -2.786 0.676 -0.737
[2,] -1.263 0.330 -0.555
[3,] -1.017 -1.020 -0.288
[4,] 3.122 0.166 -1.144
[5,] 1.955 0.788 -0.189
[6,] -0.948 1.201 1.140
[7,] -0.325 -1.755 -0.909
[8,] 0.637 1.130 0.692
[9,] 0.623 -1.517 1.991
Ces résultats sont identiques à ceux obtenus pour l'ACP. Cf. les fichiers : PSY-M1-Ana-mult-1.doc ou PSY-M1-Ana-mult-1.pdf . Les coordonnées des individus sur les 3 premiers axes factoriels sont rappelées ci-dessous :
|
|
Fact. 1 |
Fact. 2 |
Fact. 3 |
Sujet |
|
1 |
-2,7857 |
0,6765 |
0,7368 |
Jean |
|
2 |
-1,2625 |
0,3303 |
0,5549 |
Aline |
|
3 |
-1,0167 |
-1,0198 |
0,2881 |
Annie |
|
4 |
3,1222 |
0,1659 |
1,1442 |
Monique |
|
5 |
1,9551 |
0,7879 |
0,1892 |
Didier |
|
6 |
-0,9477 |
1,2014 |
-1,1401 |
André |
|
7 |
-0,3250 |
-1,7548 |
0,9095 |
Pierre |
|
8 |
0,6374 |
1,1298 |
-0,6919 |
Brigitte |
|
9 |
0,6231 |
-1,5173 |
-1,9909 |
Evelyne |
# Le MDS classique "à la main"
# Distances entre 4 villes du Danemark
P <- matrix(c(0,93,82,133,93,0,52,60,82,52,0,111,133,60,111,0),nrow=4)
# Matrice des distances au carré
P2 <- P*P
# Matrice J = I - 1/n 1
Un <- matrix(c(rep(1,16)),nrow=4)
I4 <- matrix(c(rep(c(1,0,0,0,0),3),1),nrow=4)
J <- I4 - .25 * Un
# Matrice B
B <- -0.5 * J %*% P2 %*% J
# Valeurs propres et vecteurs propres
DIAG <- eigen(B)
# Matrice Lambda^1/2 pour 2 dimensions
LPLUS <- matrix(c(sqrt(DIAG$values[1]),0,0,sqrt(DIAG$values[2])),nrow=2)
# Vecteurs propres correspondants
CPLUS <- DIAG$vectors[,1:2]
# Solution
X <- CPLUS %*% LPLUS
X
# [,1] [,2]
#[1,] 62.83108 32.97448
#[2,] -18.40289 -12.02697
#[3,] 24.96018 -39.71091
#[4,] -69.38837 18.76340
# Vérification
cmdscale(P)